アルバム・オブ・ザ・イヤー 2016
こんにちは。今年も大晦日ですね。id:dmingnに触発されて僕も今年聴いたアルバムの中からオススメのアルバム・曲を書こうかなと思いました。
彼と同じようにあくまで「僕が今年初めて聴いた」アルバムを紹介するので、必ずしも「今年出た新譜」であるとは限りません(むしろそうじゃない方が多い)。
ちなみに今年自分で購入したCDの枚数は36枚でした。一ヶ月に3枚のペースなので、まあ消化するにはそんなもんかなというペースだと思います。
第8位より上はすべて円盤で持ってるので、借りたい人は声かけてもらえればと。
第9位: THE COMPLETE HISTORIC MOCAMBO SESSION '54 -- Shotaro Moriyasu
一発目から2016年どころか62年前のアルバムで恐縮だが、このジャズ黎明期において日本のジャズシーンでこれだけのハードバップセッションがあったことに感銘を受けた。
ピアニスト守安祥太郎は33歳で夭折したそうで、現存する録音はこのアルバムしかないらしい。
廃盤になってて中古もコレクター価格でアホみたいに高く、どうにか入手したいがどうなることやら。
正直日本のジャズシーンにはほとんど興味が持てなかったが、来年は開拓してみようと思わせてくれた音源。
第8位: NIHIL NOVI -- Marcus Strickland
久々にバスクラリネット奏者を見つけたことに歓喜していた。こういうR&Bっぽい方面でバスクラリネットが使われてるのが素直にウケた。
Tim Garlandに比べるとシンプルなバスクラリネットだと感じた(Tim Garlandは「バスクラリネットでテナーサックスを吹いている」)。

- アーティスト: Marcus Strickland
- 出版社/メーカー: Bluen
- 発売日: 2016/04/15
- メディア: CD
- この商品を含むブログ (1件) を見る
第7位: Adlibs -- Christian Doepke
Christian Doepkeはオランダ出身(?)のピアニストらしく、僕は全然知らなかったのだが、パワフルなプレイがシンプルでいい。
特筆すべきはRick Margitzaのテナーサックス(むしろこれ目当てだったが)。Maria Schneider Orchestra以外で何をやってるのか詳しく知らなかったが、あれと同じようなエグみのある音が他でも聴けるとわかってよかった。Mariaの『Green Piece』にしろ、Rick Margitzaの奏でるマイナーコード一発のソロには異常な聴き応えがある。
それにしてもAvishai Cohen (b)のときもそうだったが、どうもC minor一発ものに魅了されてしまう傾向があるらしい。
第6位: Point in Time -- Fred Hersch
1995年に録音され2014年にCD版がリマスターされた本作。トリオではM7の『Cat's Paws』のドラム・ピアノのソロバトルのキレに注目。
なんといってもフロントとして参加したDave DouglasとRich Perryが見もので、M6『Infant Eyes』のRich PerryはWayne Shorterを彷彿とさせる音色で傑作。

- アーティスト: フレッド・ハーシュ
- 出版社/メーカー: SOLID/ENJA
- 発売日: 2014/07/16
- メディア: CD
- この商品を含むブログを見る
第5位: Nearness -- Joshua Redman & Brad Mehldau
デュオ編成。普段はほとんど4〜6人の編成しか聴かないのだが、今年の10月に来日公演するとのことだったので聴いてみたらハマった。
トリオ、カルテットのときに比べて脱力しつつもエネルギーのあるJoshuaの新しい一面を垣間見た気がした。
MehldauのJoshuaへの絶妙な譲歩も見もの。
第4位: ★ -- David Bowie
(ちなみに『★』はショパンのプレリュード作品番号28の4が元ネタになってると思うのだが全くソースがなく、僕の思い過ごしだろうか)
第3位: Sunday Night at the Vanguard -- Fred Hersch
2016年の3月にVillage Vanguardで行われたライブの録音が8月に発売されたアルバム。
僕は11月にライブに行ったのだが、あまりに綺麗な音色と精緻なタッチで不覚にも泣きそうになった。
CDで聴くのもオススメだが、Herschほど生音を聴くべきなピアニストもいないと思うのでライブは非常にオススメ。
![サンデイ・ナイト・アット・ザ・ヴァンガード [日本語帯/解説付] [輸入CD]](https://images-fe.ssl-images-amazon.com/images/I/518MVk8pLFL._SL160_.jpg "サンデイ・ナイト・アット・ザ・ヴァンガード [日本語帯/解説付] [輸入CD]")
サンデイ・ナイト・アット・ザ・ヴァンガード [日本語帯/解説付] [輸入CD]
- アーティスト: フレッド・ハーシュ
- 出版社/メーカー: Palmetto Records / King International
- 発売日: 2016/07/15
- メディア: CD
- この商品を含むブログを見る
第2位: Family First -- Mark Guiliana
去年のKendrick ScottにしろGuilianaにしろ、なんでドラマーのリーダー作ってこんなにメロディアスでカッコいいんだ。
どの曲も雌雄決し難いが、敢えてこれというならM4の『Long Branch』。4+4+4+3の15拍子の中で淀み無い「静」と「動」の世界観の対比が作り上げられていて感服。
テナーサックスのJason RigbyはNYCで活躍中のプレイヤーらしく、この作品に吹き込まれている音色とグルーブだけで一発で惚れた。
ちなみにM3は『2014』というタイトルだが、このアルバムが出たのは2015年で、僕が買ったのは2016年。
![Family First[ボーナストラック収録・日本語解説つき]](https://images-fe.ssl-images-amazon.com/images/I/51zcMiXcfjL._SL160_.jpg "Family First[ボーナストラック収録・日本語解説つき]")
Family First[ボーナストラック収録・日本語解説つき]
- アーティスト: Mark Guiliana
- 出版社/メーカー: AGATE
- 発売日: 2015/06/04
- メディア: CD
- この商品を含むブログを見る
第1位: Beyond Now -- Donny McCaslin
オチが見えてたので語るべくもあらず、って感じだが。『★』の残したDavid Bowieの亡霊が犇めくのでカッコよくないわけがない。
『Family First』と含めてMark Guilianaのクールさが良い。スネアの音、盛り上げ方やフロントとのバランス、正確なドラミングの裏に時折見せるレイドバックがたまらない。
McCaslinとは年始にも一度NYCで本人と言葉を交わす機会があり、2017年も2月に来日するので非常に楽しみ。
それでは2016年も残すところ12時間となりましたが、来年も良いお年を。
ネットワークスタック内の謎の2バイトについて探る
この記事はTSG Advent Calendar 2016 - Adventarの25日目として書かれました。
自分既にOBですし、25日目ともなると「何か壮大なネタを…」とか考えあぐねていたのですが、現実的なネタを思いつけなかったので最近やってたことでも書きます。
先日LinuxのNICドライバの開発についてのエントリを書いていたのですが、その与太話でもしようかなと思います。
sk_buff構造体
Linuxのカーネル内では、ネットワークパケットはsk_buff構造体によって扱われています。
(ソースコード → Linux/include/linux/skbuff.h - Linux Cross Reference - Free Electrons)
説明としては
が非常にナイスだと思います。
要点としては
- head
- data
- tail
- end
という4つのポインタがあり、実際にkmallocで確保されたメモリ領域(ここで確保されています)はhead〜endの間なのですが、ネットワークスタックやドライバの中では「その部分領域がパケットとして見える」方が便利なこともあります。
例えば、IPv4プロトコルは通常Ethernetプロトコルにのっているわけですが、場合によってはInfiniBandにのっかることもあるわけです。
そうなってくると同じIPでもバッファの何バイト目から始まるのかいちいち把握するのが面倒になるので、data〜tailの間の領域として管理します。
余談ですがIP over InfiniBandはRFC 4755 - IP over InfiniBand: Connected Modeあたりを参照するのがよいでしょう。InfiniBandは東工大のスパコンTSUBAMEでも用いられているHPC向けのインターコネクト規格ですが、バックプレーンやバス規格のみならずプロトコルまでもがHPCに最適化された規格なので、通常我々一般ユーザが手元のPCでブラウザ開いてるときに裏で流れているパケットとは異なる構造のパケットが流れているわけです。
NICドライバの最適化
何はともあれNICドライバを書いていたわけです。詳しくは先述の拙筆のエントリをご覧頂くとして、問題はパケットの送信処理を書いていたときに起こりました。
パケットの送信は、カーネルに送信すべきパケットがあるとまずあらかじめ登録したstart_xmit_frameコールバックを呼び出します。
int start_xmit_frame(struct sk_buff *skb, struct net_device *dev);
この関数には送信すべきパケットskbが渡されてくるので、これをNICに転送してやるのがドライバの役目です。当初は
int start_xmit_frame(struct sk_buff *skb, struct net_device *dev) { ... memcpy(txdesc->base_addr, skb->data, skb->len); ... }
といった感じで送信データを転送していました。txdesc->base_addrというのがNIC転送用に確保されたバッファだと思ってください。NICはDMAでこの領域を読み書きしにきます。なので非常に単純ですね。memcpyしているだけです。
なぜmemcpyする必要があるかというと、start_xmit_frameで渡されたskbはドライバが責任を持って解放しなければならないため、memcpy後にkfree_skb関数で解放してしまいます。
ただ、当然ですがmemcpyするのは非常に遅いです。memcpyの実装は例えばLinuxのv4.9を参考にすると
void *memcpy(void *dest, const void *src, size_t count) { char *tmp = dest; const char *s = src; while (count--) *tmp++ = *s++; return dest; }
Linux/lib/string.c - Linux Cross Reference - Free Electrons
となっているわけですが、単純計算1バイトコピーするごとに
- countのデクリメント1回
- tmpとsのインクリメントが1回ずつ(計2回)
- tmpとsのメモリ間転送が1回
- whileループを実現するためのジャンプ命令が1回と0比較命令が1回
発生するので、ざっくり5クロックと見積もりましょう(ごめん本当に適当だ)。一方でパケットはMTU(=Maximum Transfer Unit; 1パケットの最大送信可能サイズ。通常はEthernetなら1500[B])程度のサイズが来ることが想定されるので、ざっくり7500クロックくらい。
昨今のCPUの周波数、これも適当に2GHzとか見積もってやるとだいたい3.75マイクロ秒くらいコピーにかかるのです。
「たかが4マイクロ秒」というかもしれませんが、例えば当ブログのトップページは現在執筆時点で103[KB]だったので、
(103 * 10^3)[B] * 5[clk] * 0.5[ns] / 10^6 = 0.2575[ms]
とかになるわけで、ドライバの功罪が最終的に0.3ミリ秒程度のレスポンス低下を招くわけです(計算は適当なのでスマン)。
ではどうするかというと、逆にmemcpyせずにskbを直接NICへの転送領域に指定してしまうわけです。つまり、memcpyの代わりに
txdesc->base_addr = skb->data;
とします(実際には仮想アドレス云々でちょっと違いますが、動作イメージとしてはこうです)。
聡明な読者諸君は「さっきskbはドライバが解放しないといけないって言ったじゃん!どうやって解放するの?」という疑問を抱かれることかと思います。
これに関しては、大抵のNICは送信完了時に送信完了割込みを発生させるので、そのときまで未解放のskbを持っておいて、送信完了が分かった時点で解放してしまえばいいのです。
しかし動かない
あとは簡単、ドライバをビルドしてテストするだけ、だと思ってたのですが、うまくいきませんでした。
パケットを送信しようとしても、Ethernetヘッダの前に謎の2バイトがくっつくという謎のバグが発生しました。

このドライバを通るすべての送信パケットでこの現象が発生するので、そもそもpingが通る云々以前にARP requestすらもロクに送れないのです。
原因を探る
まずはskb->dataの(物理)アドレス値をダンプしてみました。すると、下1桁がすべて2になっています。
ここで1つ思い当たったのがDMAの制約です。今回のNICはARM向けで、NICはAXIバス(ARMのバス規格)で接続しています。
AXIバスは8バイト境界でしか転送が行えないため、下1桁が2のアドレス値を渡しても切り捨てされたアドレス値で転送してしまい、結果として先頭にゴミ2バイトがついてしまうということはわかりました。

しかし、そもそもなぜアドレス値の下1桁がすべて2になっているのか?
次にskb->headのアドレス値をダンプしてみました。こっちは下1桁が0にちゃんとなっているんですよね。つまり、カーネルのネットワークスタック内で謎の2バイトがheadとdataの中に挿入されているわけです。

じゃあなんでネットワークスタック内で2バイト入れられてるのかというと、答えはこのマクロでした。
Linux/include/linux/skbuff.h - Linux Cross Reference - Free Electrons
#define NET_IP_ALIGN 2
これ何かというと、sk_buffを確保しているときに2バイトだけアラインメントを入れているんですね。例えばalloc_skb関数のラッパーとしてこんなのがあります。
static inline struct sk_buff *__netdev_alloc_skb_ip_align(struct net_device *dev, unsigned int length, gfp_t gfp) { struct sk_buff *skb = __netdev_alloc_skb(dev, length + NET_IP_ALIGN, gfp); if (NET_IP_ALIGN && skb) skb_reserve(skb, NET_IP_ALIGN); return skb; }
Linux/include/linux/skbuff.h - Linux Cross Reference - Free Electrons
skb_reserve関数はskb->dataを指定バイト数だけ進めてヘッダ領域を確保する関数です(生のhead / data / tail / endを扱うのは望ましくない)。ご丁寧にそもそも2バイト多く確保して、頭に2バイトくっつけてるのです。
これはTCP/IPのせせこましい歴史的経緯に由来しています。ところでみなさん、Ethernetヘッダって何バイトか覚えてますか?(これで2バイトの意味がわかったら相当すごいと思うんですが)
struct ethhdr { unsigned char h_dest[ETH_ALEN]; /* destination eth addr */ unsigned char h_source[ETH_ALEN]; /* source ether addr */ __be16 h_proto; /* packet type ID field */ } __attribute__((packed));
Linux/include/uapi/linux/if_ether.h - Linux Cross Reference - Free Electrons
ちなみにIPv4ヘッダはこんな構造になっております。
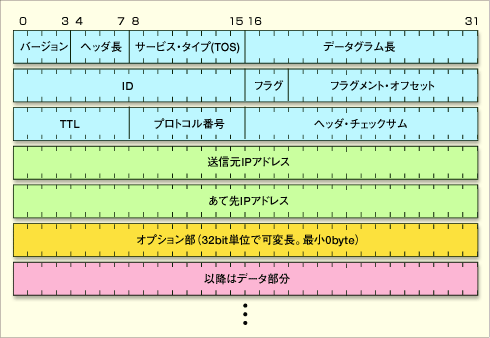
基礎から学ぶWindowsネットワーク:第10回 IPパケットの構造とIPフラグメンテーション (2/3) - @IT
注目してほしいのは「送信元IPアドレス」「宛先IPアドレス」です。これらはIPヘッダ内では4バイトアラインになっています。
しかし、Ethernetヘッダが頭にくっつくと、Ethernetヘッダ長が14バイトという中途半端な値ゆえ、4バイトアラインではなくなってしまいます。
多くのアーキテクチャでは4バイトアラインになってないメモリアクセス(アラインメント違反)を起こすと(キャッシュを何回もひかないといけないなどの事情で)パフォーマンスが低下します。
送信元IPアドレスや宛先IPアドレスはカーネルも頻繁にアクセスするため、できればアラインメント違反は起こしたくないので、それを避けるためにわざわざ2バイトのIPアラインを挿入しているのです。
ただし、これは古いアーキテクチャの話で、最近のx86だとかPowerPCだとアラインメント違反に起因するパフォーマンス低下はそこまででもないため、NET_IP_ALIGNは0になっています。
Linux/arch/powerpc/include/asm/processor.h - Linux Cross Reference - Free Electrons
Linux/arch/x86/include/asm/processor.h - Linux Cross Reference - Free Electrons
この辺(↑)参照。
Linuxネットワークドライバの開発
この記事はLinux Advent Calendar 2016 9日目の記事です。
遅刻してしまい申し訳ございません。。。

とある事情があって1ヶ月半ほど独自NICのLinux向けのネットワークドライバを開発していた。
今回はARM用のデバイスドライバを開発した。NICはXilinx社のFPGAであるZYBOを用いて開発した。
まだ十分に実用段階というわけではないが、ひとまず独自NIC経由でのpingやiperfが通ったので、後学のために知見を残しておきたい(誰得だ、という感じだが)。
ソースコードはまだ公開されていないが、そう遠くないうちに公開する予定(たぶん)。
はじめに
の3種類がある。ネットワークデバイスはブロック単位の通信を行うという点ではブロックデバイスと共通しているのだが、ブロックデバイスとは違い
- /dev以下にはマウントされない
- システムコールのインターフェースが違う(e.g. ブロックデバイスはopenで開けるがネットワークデバイスは異なる)
- デバイスからも非同期的にカーネルアクセスが発生する(e.g. DMA)
といった相違点がある。このあたりに"Everything is a file"というLinuxのポリシーとの矛盾が発生しているわけだが。
さて、ネットワークドライバに最低限必要な機能は
- デバイスの取得及び各種設定
- パケット送信
- パケット受信
といったあたりである。
また、ハイエンド通信ではパケット受信時にいちいちNICからの割込みトリガーで動いていてはパフォーマンスが上がらないので、ポーリングに切り替える方法(NAPI)も説明する。
これらに加えて、ビルドの方法を明記しておきたい。というのも、デバイスドライバはカーネルモジュールとしてLinuxに登録されるわけだが、このカーネルモジュールは一般的なプログラムとビルドの方法がだいぶ違う。
以下、環境は次の通りである。
ビルド
まずはカーネルモジュールのビルド方法を示す。LDD3の2章を参考にしながら進める。
#include <linux/init.h> #include <linux/module.h> MODULE_LICENSE("MIT"); static int voltx_init(void) { printk("voltx loaded\n"); return 0; } static void voltx_exit(void) { printk("voltx unloaded\n"); } module_init(voltx_init); module_exit(voltx_exit);
さて、カーネルモジュールをビルドするためには専用のMakefileが必要になる。
KERNEL_SOURCE=/lib/modules/$(shell uname -r)/build obj-m += voltx.o all: make -C $(KERNEL_SOURCE) M=$(PWD) modules clean: make -C $(KERNEL_SOURCE) M=$(PWD) clean
このようなMakefileを作ってmakeコマンドを叩くとvoltx.koというカーネルモジュールがビルドされる。
カーネルモジュールをロード/アンロードするにはinsmod/rmmodコマンドを使う。
$ make $ insmod voltx.ko $ lsmod Module Size Used by voltx 12496 0
このように、lsmodコマンドを使うとモジュールがロードされていることが確認できる。insmodには管理者権限が必要になるはず。
printkした内容はdmesgコマンドで確認できる。もしくは/var/log/syslogの内容を直接確認する。これはカーネルモジュールにおけるprintfデバッグの手段となる。
ちなみに分割コンパイルを行う場合は、MakefileにEXTRA_CFLAGSという変数という変数とvoltx-objs([モジュール名]-objs)という変数を追加する。
EXTRA_CFLAGS=-I(include pathをここに指定) voltx-objs := source1.o source2.o ...
EXTRA_CFLAGSはカーネルモジュールビルド時にgccに対して追加で指定するオプション群である。インクルードパスの設定はこの変数を通して行える。
【参考】LDD3 chapter 2
デバイスの取得と設定
NICは通常PCIe経由で接続されていることが多いが、今回はZYBO上なのでAXI Bus経由になる。
AXIとはARM用のバスの規格であるが、歴史的経緯によりARMのデバイス情報はLinuxのソースコード本体からは隔離され、Device Treeというファイルに隔離されている。
デバイスドライバはDevice Treeからデバイス情報を取得する。例えばIRQやMMIO base addressを取得してデバイスドライバに設定する、といった具合だ。
FPGAを用いて開発されたデバイスの場合でもDevice Treeが存在する。本記事ではFPGA側のDevice Treeの作成については触れず、既にDevice Treeが作られている前提とする。
また、PCIe経由でのデバイスの取得については現在未対応なので、後日別の記事にする予定。
基本的には次の記事を参考にする。
ドライバ側で必要なのは、module_platform_driverマクロを使ってof_device_id構造体とplatform_driver構造体を登録することだ。
static const struct of_device_id voltx_of_match[] = { { .compatible = VOLTX_COMPATIBLE_FIELD,}, {}, }; static struct platform_driver voltx_driver = { .probe = voltx_probe, .remove = voltx_remove, .driver = { .name = DRIVER_NAME, .of_match_table = voltx_of_match, }, }; module_platform_driver(voltx_driver);
DRIVER_NAMEはドライバ側で任意に決めてよい。VOLTX_COMPATIBLE_FIELDはDevice Treeと同じものを設定する必要がある。
voltx_probeとvoltx_removeはそれぞれinsmod/rmmod時に呼ばれるコールバック関数だ。関数シグネチャはそれぞれ次のようになる。
static int driver_probe(struct platform_device *); static int driver_remove(struct platform_device *);
probeではデバイスの初期化および各種設定、removeではその逆を行ったりドライバが確保したメモリを解放したりする。
ここではまず、Device TreeからIRQとMMIO base addressの取得を行う。MMIO base addressとはMMIOによってホストマシンの仮想メモリ上にマッピングされたデバイスのレジスタにアクセスするための、ベースアドレスである。実際にはレジスタのオフセット値を足して読み書きする。
#include <linux/platform_device.h> #include <linux/inetdevice.h> #include <linux/etherdevice.h> #include <linux/interrupt.h> #include <linux/irq.h> #include <linux/of_irq.h> /** network device */ struct net_device *voltx_dev; /** platform device used for DMA configuration */ struct platform_device *pdev; static int voltx_remove(struct platform_device *op) { if (voltx_dev) { unregister_netdev(voltx_dev); free_netdev(voltx_dev); } // success printk(KERN_INFO "voltx is unloaded.\n"); return 0; } static int voltx_probe(struct platform_device *op) { int result = -1; int irq = -1; struct resource *res = NULL; pdev = op; // open device tree res = platform_get_resource(op, IORESOURCE_MEM, 0); if (res == NULL) { return -ENOMEM; } else { printk("voltx: platform_device = %pR\n", res); } // check IRQ specified by device tree irq = irq_of_parse_and_map(op->dev.of_node, 0); if (irq == NO_IRQ) { dev_err(&op->dev, "voltx: error while mapping IRQ\n"); return -EINVAL; } // request mem region (preferred to be executed before ioremap) if (!devm_request_mem_region(&op->dev, res->start, VOLTX_CONFIG_SPACE_SIZE, DRIVER_NAME)) { dev_err(&op->dev, "voltx: error while requesting mem region\n"); result = -EBUSY; goto err; } if (dma_set_coherent_mask(&op->dev, DMA_BIT_MASK(32)) != 0) { dev_err(&op->dev, "voltx: error while setting DMA coherent mask\n"); result = -EBUSY; goto err; } // allocation voltx_dev = alloc_etherdev(sizeof(struct voltx_adapter)); if (voltx_dev == NULL) { result = -ENOMEM; goto err; } else { // set I/O base address voltx_dev->base_addr = res->start; // set IRQ voltx_dev->irq = irq; } // register (voltx_dev MUST be initialized by voltx_setup() beforehand) if ((result = register_netdev(voltx_dev)) != 0) { printk("voltx: error %i while registering network device\n", result); voltx_remove(op); result = -ENODEV; goto err; } // success printk(KERN_INFO "voltx is loaded.\n"); return 0; err: irq_dispose_mapping(irq); return result; }
voltx_probe内でやっていることは以下の流れの通り。
- platform_get_resource → Device Treeの情報を取得
- irq_of_parse_and_map → IRQの取得
- devm_request_mem_region → MMIO領域の取得 (VOTLX_CONFIG_SPACE_SIZEはあらかじめ決めたデバイスのレジスタ領域のサイズを指定)
- dma_set_coherent_mask → MMIO領域をDMA coherentに設定
- alloc_etherdev → Ethernetデバイスを確保
地味に重要なのがdma_set_coherent_maskを呼ぶことになる。MMIO領域はDMAでデバイス・ドライバ双方からアクセスするわけだが、この領域にキャッシュが効いてしまうとデバイスとドライバで読み書きしている内容に一貫性が取れなくなってしまう。
そのため、キャッシュ無効化領域に設定するのがこの関数である。これを呼ばないと、NIC側から書いたはずのデータがドライバ側から全く読めないという現象が起こる。
Device Tree関連の設定を行うと、x86上ではコンパイルできなくなってしまう。ARM上で直接コンパイルするか、もしくはクロスコンパイルを行う。
今回利用しているのはDigilent社が公開しているSoC用のLinuxソースコードである。
これをcloneし(回線速度によるが相当時間がかかる)、make時のオプションに指定する。
先程示したMakefileにKERNEL_SOURCEという変数があったが、これをmakeのオプションで上書きする。
$ make ARCH=arm KERNEL_SOURCE=/path/to/linux-Digilent-Dev
ARM用のクロスコンパイラも必要になるが、その用意方法については割愛する。基本的にはVivado SDKをインストールすればarm-xilinx-linux-gnueabi-*のツールチェインがインストールされるはずである。
ちなみにDevice Tree関連のモジュールがどうやらGPLで開発されているらしいので、この辺の関数を使うとライセンスをGPLに変更することが強制されるようになる(ライセンス変更しないとビルドできない)。
さて、ここまででデバイスの情報をDevice Tree経由で取得し、Ethernetデバイスの初期化を行った。ここから実際にネットワークドライバの処理を記述していく。
ネットワークドライバの基本設計
ネットワークドライバの仕事は、基本的にはプロトコルスタックから受け取ったパケットをデバイスに渡し、デバイスがDMAで書き込んできたパケットをプロトコルスタックに移譲するだけである。
その前にまずはデバイスをネットワークインターフェースとして認識できるようにしよう。この手順が終われば、ifconfigでネットワークインターフェースとして登録したり、IPアドレスを設定したりできるようになる。
そのためにはいくつかコールバック関数を定義する必要がある。
struct voltx_adapter { /** platform device used for DMA configuration */ struct platform_device *pdev; /** packet tx/rx statistics information */ struct net_device_stats stats; /** spinlock */ spinlock_t lock; /** network device */ struct net_device *dev; /** configuration space size */ int config_size; /** configuration space address */ uint32_t *config_addr; }; static const struct net_device_ops voltx_netdev_ops = { .ndo_open = voltx_open, .ndo_stop = voltx_stop, .ndo_start_xmit = voltx_tx, .ndo_get_stats = voltx_get_stats, }; struct net_device_stats *voltx_get_stats(struct net_device *dev) { struct voltx_adapter *adapter = netdev_priv(dev); return &adapter->stats; } void voltx_setup(struct net_device *dev) { struct voltx_adapter *adapter; // set up device interfaces dev->netdev_ops = &voltx_netdev_ops; // initialize private fields adapter = netdev_priv(dev); adapter->dev = dev; adapter->pdev = pdev; }
まずいくつか説明を行う。最低限定義しなければならないコールバックは
- open(ifconfig upでインターフェースを登録したときに呼ばれる)
- stop(ifconfig downでインターフェースを削除したときに呼ばれる)
- start_xmit(パケット送信時に呼ばれる)
- get_stats(ifconfigで表示されるインターフェース情報を返す)
「パケット受信時は?」と思うかもしれないが、基本的にパケット受信時はデバイスからの割込みが発生するので、割り込みハンドラから受信パケット処理関数を呼び出すようにする。
voltx_setupはvoltx_probeでvoltx_devを初期化した後に呼び出せばよい。
まずは一番簡単なget_statsを説明する。voltx_adapter構造体という謎の構造体を定義しているが、これは"netdev private"と呼ばれる情報である。
net_device構造体はできるだけ種々のネットワークデバイスを抽象化しているが、それでもデバイス依存の部分は多々存在するので、抽象化によって吸収できなかった部分を個々のデバイスごとに勝手に定義するものがnetdev privateである。
この中にifconfigで取得できるデバイス情報を表すnet_device_stats構造体の変数を作る。
netdev privateはnet_deviceに対してnetdev_priv関数を呼ぶと取得することができる。
次にopenについて説明する。openでやらなければならないことはパケット送受信の開始を通知するnetif_start_queue関数を呼ぶことだけであるが、ついでなので種々の設定も行う。
#ifdef __arm__ #define voltx_write(func, dev, reg, val) \ func(val, (uint8_t *)(((struct voltx_adapter *)netdev_priv(dev))->config_addr) + reg) #define voltx_read(func, dev, reg) \ func((uint8_t *)(((struct voltx_adapter *)netdev_priv(dev))->config_addr) + reg) #else // e.g. x86 // do nothing since no corresponding actual hardware exists #define voltx_write(func, dev, reg, val) #define voltx_read(func, dev, reg) 0 #endif #define voltx_writeb(dev, reg, val) voltx_write(writeb, dev, reg, val) #define voltx_writew(dev, reg, val) voltx_write(writew, dev, reg, val) #define voltx_writel(dev, reg, val) voltx_write(writel, dev, reg, val) // you must split 64-bit-qword into 2 32-bit-words because root complex // discards 64-bit-qword #define voltx_writeq(dev, reg, val) { \ voltx_writel((dev), (reg), (val) & 0xffffffff); \ voltx_writel((dev), (reg) + 4, (val) >> 32); \ } #define voltx_readb(dev, reg) voltx_read(readb, dev, reg) #define voltx_readw(dev, reg) voltx_read(readw, dev, reg) #define voltx_readl(dev, reg) voltx_read(readl, dev, reg) #define voltx_readq(dev, reg) \ (voltx_readl(dev, reg)) | ((voltx_readl(dev, reg + 4)) << 32) static inline uint32_t inet_atol(uint8_t *a) { #if __BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__ return (a[0] << 24) | (a[1] << 16) | (a[2] << 8) | a[3]; #elif __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__ return (a[3] << 24) | (a[2] << 16) | (a[1] << 8) | a[0]; #else #error "Endian not supported." #endif } int voltx_open(struct net_device *dev) { struct voltx_adapter *adapter = netdev_priv(dev); int ret; uint32_t hadr0; uint32_t hadr1; uint8_t *ipaddr; // DMA setup adapter->config_size = VOLTX_CONFIG_SPACE_SIZE; adapter->config_addr = ioremap_nocache(dev->base_addr, adapter->config_size); // fetch MAC address hadr0 = voltx_readl(dev, REG_HADR0); hadr1 = voltx_readl(dev, REG_HADR1); dev->dev_addr[0] = hadr0 & 0xff; dev->dev_addr[1] = (hadr0 >> 8) & 0xff; dev->dev_addr[2] = (hadr0 >> 16) & 0xff; dev->dev_addr[3] = (hadr0 >> 24) & 0xff; dev->dev_addr[4] = hadr1 & 0xff; dev->dev_addr[5] = (hadr1 >> 8) & 0xff; // set IPv4 address ipaddr = (uint8_t *)&dev->ip_ptr->ifa_list->ifa_local; voltx_writel(dev, REG_PADR0, inet_atol(ipaddr)); // register interrupt handler if ((ret = request_irq(dev->irq, voltx_intr, IRQF_SHARED, dev->name, dev))) { printk("voltx: unable to register IRQ %d\n", dev->irq); return ret; } else { irq_set_irq_type(dev->irq, IRQ_TYPE_EDGE_RISING); } netif_start_queue(dev); return 0; }
今回はMACアドレスをデバイスから取得し、IPアドレスをデバイスに対して設定している。具体的なレジスタのオフセット値はデバイスごとによって決まっている。
IPアドレスの取得の仕方は非常にトリッキーだが、そういうものだと思って欲しい(参照ソースをメモし忘れた)。
ここで重要なのは、レジスタ(もといMMIO領域)へのアクセスの仕方である。以下の資料を参考にする。
MMIO領域はまずioremap_nocache関数で開ける必要がある。先程取得してdev->base_addrに設定したアドレスは物理アドレスなので、これで初めて仮想アドレスに変換される。
この領域にアクセスするには、上記の資料で説明されているようにioread/iowriteを使う。それをwrapしたマクロがvoltx_read/voltx_writeである。
その後、request_irq関数で割り込みハンドラを設定している。IRQはDevice Treeから取得した番号を設定している。割り込みハンドラであるvoltx_intr関数については「パケット受信」(後述)で説明する。
stopは以下の通りである。
int voltx_stop(struct net_device *dev) { struct voltx_adapter *adapter = adapter_of(dev); free_irq(dev->irq, dev); netif_stop_queue(dev); iounmap(adapter->config_addr); return 0; }
やっていることはopenの逆なので説明は割愛する。
start_xmitについては次の「パケット送信」で説明する。
パケット送信
このあたりになってくるとdevice-specificなので一般的な説明は難しい。今回作ったNICの基本構造はIntel NIC (e1000)を参考にしているので、送受信時にはe1000の持つリングバッファ機構と同じ機構を持っている。
Intel NIC (8254x)のSoftware Developers Manualを参考にするとよい。
http://www.intel.co.za/content/dam/doc/manual/pci-pci-x-family-gbe-controllers-software-dev-manual.pdf
(なぜかIntelの公式ページからリンクが辿れなくなっている…)
基本的にはtx (rx) descriptorと呼ばれる、送信(受信)パケットをバッファアドレスや長さを示した構造体があり、これがリングバッファを形成している。
リングバッファ自体のアドレスとhead/tail、及びdepthがデバイスのレジスタとして設定できるようになっている。これらのレジスタ値はデバイスの初期化時に設定する。
/** * Transmission packet descriptor. */ struct voltx_tx_desc { /** base address of beginning of the packet */ uint32_t base_addr; uint32_t base_addr0; /** packet size */ uint16_t size; /** reserved */ uint8_t reserved[6]; } __attribute__((packed));
送信時はheadを1つ進めて対応するtx descriptorに対して送信バッファアドレスとパケット長を設定するだけである。あとはデバイスがよしなにやってくれる。
ここで注意しなければならないのは、descriptorのリングバッファはデバイスからもアクセスされるという点である。
つまり、DMA coherentでなければならない。でないと、ドライバが書いたつもりのパケットが書かれなかったりする。これに関しては次のページを参考にする。
要点はこうだ。
- DMA coherentにしたい領域はdma_alloc_coherent関数で確保し、dma_free_coherent関数で開放
- 領域に書き込む前にdma_map_single関数を呼び、読み出した後はdma_unmap_single関数を呼ぶ
さて、最初にパケット送信用のコールバック(start_xmit, voltx_tx)を登録したので、その説明を行う。
#include <linux/ip.h> #include <linux/tcp.h> #include <linux/udp.h> #include <net/tcp.h> /** * Calculate checksum. */ void voltx_tx_csum(struct sk_buff *skb) { struct ethhdr *ethh = (struct ethhdr *)skb->data; if (ethh->h_proto == htons(ETH_P_IP)) { struct iphdr *iph = ip_hdr(skb); switch (iph->protocol) { case IPPROTO_TCP: { struct tcphdr *tcph = tcp_hdr(skb); int tcplen = skb->len - (iph->ihl << 2) - ETH_HLEN; tcph->check = 0; skb->csum = csum_partial((uint8_t *)tcph, tcplen, 0); tcph->check = csum_tcpudp_magic( iph->saddr, iph->daddr, tcplen, IPPROTO_TCP, skb->csum); skb->ip_summed = CHECKSUM_NONE; break; } case IPPROTO_UDP: udp_hdr(skb)->check = 0; break; } iph->check = 0; iph->check = ip_fast_csum((uint8_t *)iph, iph->ihl); } } /** * Device-independent transmission sequnece. */ int voltx_tx(struct sk_buff *skb, struct net_device *dev) { struct voltx_adapter *adapter = netdev_priv(dev); // manually calculate checksum voltx_tx_csum(skb); // manually calculate checksum if (skb->len < ETH_ZLEN) { if (skb_pad(skb, ETH_ZLEN - skb->len)) { return NETDEV_TX_OK; } } // jiffies (timestamp) is counted up by kernel dev->trans_start = jiffies; // device-specific transimission sequence if (voltx_hw_tx(dev, skb->data, skb->len) < 0) { adapter->stats.tx_dropped++; return NETDEV_TX_OK; } // if you use tx interrupt, you should update stats in interrupt handler adapter->stats.tx_packets++; adapter->stats.tx_bytes += skb->len; return NETDEV_TX_OK; }
start_xmitはskbという形で送信パケットを渡される。このsk_buff(よくskbと表記される)はカーネル・プロトコルスタック内でのパケットを表す構造体である。詳しくはHow SKBs workを参照のこと。
その次にTCP/UDP/IPチェックサムの計算を行っている。プロトコルスタック内ではチェックサムの計算は行われないようだ。理由はよくわからないのだが、おそらくチェックサムの計算は頻繁にハードウェアオフローディングが行われるため、デバイスにより密結合しているドライバ層で行うのが適当だと考えられているのだと思う。
続いてshort packet paddingを行っている。Ethernetでは60オクテット(=ETH_ZLEN)未満(FCSを含めると64オクテット未満)のパケットをshort packet、すなわち異常なパケットとして扱い、破棄する。
そのため60オクテット未満のパケットは0でパディングを行う必要がある。ARPやSYNなど、それなりのパケットは60オクテット未満である。
voltx_hw_tx関数については割愛。先述したリングバッファの処理を行う。
最後に送信済みパケット数とバイト数を増やす。これはifconfigで表示されるインターフェース情報に反映される。
ちなみに、start_xmitの戻り値は基本的にはすべてNETDEV_TX_OKとする。一応NETDEV_TX_BUSYという戻り値も定義されているのだが、これは相当深刻なエラーが発生したと扱われてしまうので、通常は返すべきではない。
パケット受信
パケット受信も基本的には送信時と同じようにrx descriptorのリングバッファに対する操作なのだが、送信と異なるのは割込みハンドラを設定する必要がある点だ。
ハンドラ(voltx_intr)の設定はvoltx_openで既に行った。
/** * Toggle receive interrupts. */ static void voltx_rx_ints(struct net_device *dev, int enable) { struct voltx_adapter *adapter = netdev_priv(dev); adapter->rx_int_enabled = enable; } /** * Interruption handler. */ irqreturn_t voltx_intr(int irq, void *dev_id) { int statusword; struct net_device *dev = (struct net_device *)dev_id; struct voltx_adapter *adapter = netdev_priv(dev); spin_lock(&adapter->lock); statusword = adapter->rx_int_enabled; if (statusword) { // disable further interrupts to enter polling mode voltx_rx_ints(dev, 0); // パケットを受信した後、割込みを有効にする } spin_unlock(&adapter->lock); return IRQ_HANDLED; }
割込み処理中はスピンロックをかけ、新規の割込みを受け付けないようにする。パケットの受信例を次に示す。
/** * Device-independent receive sequence. */ void voltx_rx(struct net_device *dev, uint8_t *buf, int len) { struct sk_buff *skb; struct voltx_adapter *adapter = adapter_of(dev); skb = netdev_alloc_skb_ip_align(dev, len); if (!skb) { adapter->stats.rx_dropped++; return; } memcpy(skb_put(skb, len), buf, len); // write metadata and pass to receive level skb->dev = dev; skb->protocol = eth_type_trans(skb, dev); adapter->stats.rx_packets++; adapter->stats.rx_bytes += (len - 4); // ignore FCS // feeds a packet into kernel (NAPI-compliant) netif_receive_skb(skb); }
skbを確保してそこに受信データをコピーし、netif_receive_skb関数を呼び出して上位のプロトコルスタックに移譲する。
memcpyの呼び出しの中でskb_put関数を呼び出しているが、これはskbの内部ポインタを調整するためである。詳しくは先程示したHow SKBs workを参照。
ハイエンド通信対応(NAPI)
ここまでで既にネットワークドライバとしては機能するのだが、さらにハイエンド通信へと対応するには受信時にポーリングに移行する必要がある。
これまではパケット受信は割込みドリブンで行っていたが、パケットの到達量が極端に増えると割込みのオーバーヘッドのせいでパケットを取りこぼしてしまうからだ。
ポーリングに切り替えるためにはNAPIというAPIを使う(New APIという身も蓋もないネーミングだ)。
NAPIを導入すれば、最終的には最初の1パケットが到達した時点だけ割込みが発生し、後は到達パケットがなくなるまでポーリングで捌き切ることができる。
まずはドライバの初期化時にNAPIを有効化する。
struct voltx_adapter { ... /** temporary buffer for rx used in polling */ uint8_t *rx_buffer; /** NAPI struct */ struct napi_struct napi; ... }; void voltx_setup(struct net_device *dev) { ... // init NAPI netif_napi_add(dev, &adapter->napi, voltx_poll, pool_size); napi_enable(&adapter->napi); ... }
これでポーリング時のコールバックとしてvoltx_poll関数が登録される。pool_sizeは1度のポーリングで処理する最大パケット数を指定する。
次に割り込みハンドラを変更する。
/** * Interruption handler. */ irqreturn_t voltx_intr(int irq, void *dev_id) { int statusword; struct net_device *dev = (struct net_device *)dev_id; struct voltx_adapter *adapter = adapter_of(dev); spin_lock(&adapter->lock); statusword = adapter->rx_int_enabled; if (statusword) { // disable further interrupts to enter polling mode voltx_rx_ints(dev, 0); napi_schedule(&adapter->napi); } spin_unlock(&adapter->lock); return IRQ_HANDLED; }
napi_schedule関数を呼び出すと、NAPIが起動しポーリングへ移行する。すなわち先程登録したvoltx_poll関数が呼び出される。
static int voltx_poll(struct napi_struct *napi, int budget) { int work_done = 0; struct voltx_adapter *adapter = container_of(napi, struct voltx_adapter, napi); struct net_device *dev = adapter->dev; int ret = 0; while (work_done < budget) { if ((ret = voltx_hw_rx(dev, adapter->rx_buffer, VOLTX_MAXIMUM_RX_BUFFER_SIZE)) < 0) { // no further packets can be received break; } else { voltx_rx(dev, adapter->rx_buffer, ret); work_done++; } } if (work_done < budget) { // if we proccessed all packets, tell the kernel and reenable interrupts napi_complete(napi); voltx_rx_ints(dev, 1); } // reached kernel upper-bound and could not process further more return work_done; }
ポーリングの処理は非常に単純で、とにかくパケットがなくなるまで受信処理を行い続ける。
処理が終わったらnapi_complete関数を呼んでパケット受信処理の終了をカーネルへ通知する。
ドライバの起動
通常通りifconfigを使ってインターフェースを起動する。
$ ifconfig eth1 192.168.0.1
するとifconfigでインターフェース情報が見れるようになる。eth1が既に存在する場合はeth2, eth3, ... , ethNを指定すればよい。
このへんのインクリメントはalloc_etherdevを使ってEthernetデバイスとして登録しているので、よしなにやってくれる。
停止するときはいつもどおり
$ ifconfig eth1 down
近くのノードに対してpingを打ってみて疎通することを確認。
参考
開発の前に読んでおきたい資料たち。
- Linux Device Drivers, Third Edition [LWN.net] (15章, 17章を読んでおくのがオススメ)
- 9.4. Using I/O Memory
- Device Tree についてのまとめ - Qiita
- [stackoverflow] Linux DMAドライバのインスタンス化および利用方法 - Qiita

- 作者: Jonathan Corbet,Alessandro Rubini,Greg Kroah-Hartman,山崎康宏,山崎邦子,長原宏治,長原陽子
- 出版社/メーカー: オライリージャパン
- 発売日: 2005/10/22
- メディア: 単行本
- 購入: 2人 クリック: 43回
- この商品を含むブログ (35件) を見る
結局は既存のドライバのソースコードを読むのが一番確実だったりするので、参考になりそうなものをいくつか挙げておく。