ネットワークスタック内の謎の2バイトについて探る
この記事はTSG Advent Calendar 2016 - Adventarの25日目として書かれました。
自分既にOBですし、25日目ともなると「何か壮大なネタを…」とか考えあぐねていたのですが、現実的なネタを思いつけなかったので最近やってたことでも書きます。
先日LinuxのNICドライバの開発についてのエントリを書いていたのですが、その与太話でもしようかなと思います。
sk_buff構造体
Linuxのカーネル内では、ネットワークパケットはsk_buff構造体によって扱われています。
(ソースコード → Linux/include/linux/skbuff.h - Linux Cross Reference - Free Electrons)
説明としては
が非常にナイスだと思います。
要点としては
- head
- data
- tail
- end
という4つのポインタがあり、実際にkmallocで確保されたメモリ領域(ここで確保されています)はhead〜endの間なのですが、ネットワークスタックやドライバの中では「その部分領域がパケットとして見える」方が便利なこともあります。
例えば、IPv4プロトコルは通常Ethernetプロトコルにのっているわけですが、場合によってはInfiniBandにのっかることもあるわけです。
そうなってくると同じIPでもバッファの何バイト目から始まるのかいちいち把握するのが面倒になるので、data〜tailの間の領域として管理します。
余談ですがIP over InfiniBandはRFC 4755 - IP over InfiniBand: Connected Modeあたりを参照するのがよいでしょう。InfiniBandは東工大のスパコンTSUBAMEでも用いられているHPC向けのインターコネクト規格ですが、バックプレーンやバス規格のみならずプロトコルまでもがHPCに最適化された規格なので、通常我々一般ユーザが手元のPCでブラウザ開いてるときに裏で流れているパケットとは異なる構造のパケットが流れているわけです。
NICドライバの最適化
何はともあれNICドライバを書いていたわけです。詳しくは先述の拙筆のエントリをご覧頂くとして、問題はパケットの送信処理を書いていたときに起こりました。
パケットの送信は、カーネルに送信すべきパケットがあるとまずあらかじめ登録したstart_xmit_frameコールバックを呼び出します。
int start_xmit_frame(struct sk_buff *skb, struct net_device *dev);
この関数には送信すべきパケットskbが渡されてくるので、これをNICに転送してやるのがドライバの役目です。当初は
int start_xmit_frame(struct sk_buff *skb, struct net_device *dev) { ... memcpy(txdesc->base_addr, skb->data, skb->len); ... }
といった感じで送信データを転送していました。txdesc->base_addrというのがNIC転送用に確保されたバッファだと思ってください。NICはDMAでこの領域を読み書きしにきます。なので非常に単純ですね。memcpyしているだけです。
なぜmemcpyする必要があるかというと、start_xmit_frameで渡されたskbはドライバが責任を持って解放しなければならないため、memcpy後にkfree_skb関数で解放してしまいます。
ただ、当然ですがmemcpyするのは非常に遅いです。memcpyの実装は例えばLinuxのv4.9を参考にすると
void *memcpy(void *dest, const void *src, size_t count) { char *tmp = dest; const char *s = src; while (count--) *tmp++ = *s++; return dest; }
Linux/lib/string.c - Linux Cross Reference - Free Electrons
となっているわけですが、単純計算1バイトコピーするごとに
- countのデクリメント1回
- tmpとsのインクリメントが1回ずつ(計2回)
- tmpとsのメモリ間転送が1回
- whileループを実現するためのジャンプ命令が1回と0比較命令が1回
発生するので、ざっくり5クロックと見積もりましょう(ごめん本当に適当だ)。一方でパケットはMTU(=Maximum Transfer Unit; 1パケットの最大送信可能サイズ。通常はEthernetなら1500[B])程度のサイズが来ることが想定されるので、ざっくり7500クロックくらい。
昨今のCPUの周波数、これも適当に2GHzとか見積もってやるとだいたい3.75マイクロ秒くらいコピーにかかるのです。
「たかが4マイクロ秒」というかもしれませんが、例えば当ブログのトップページは現在執筆時点で103[KB]だったので、
(103 * 10^3)[B] * 5[clk] * 0.5[ns] / 10^6 = 0.2575[ms]
とかになるわけで、ドライバの功罪が最終的に0.3ミリ秒程度のレスポンス低下を招くわけです(計算は適当なのでスマン)。
ではどうするかというと、逆にmemcpyせずにskbを直接NICへの転送領域に指定してしまうわけです。つまり、memcpyの代わりに
txdesc->base_addr = skb->data;
とします(実際には仮想アドレス云々でちょっと違いますが、動作イメージとしてはこうです)。
聡明な読者諸君は「さっきskbはドライバが解放しないといけないって言ったじゃん!どうやって解放するの?」という疑問を抱かれることかと思います。
これに関しては、大抵のNICは送信完了時に送信完了割込みを発生させるので、そのときまで未解放のskbを持っておいて、送信完了が分かった時点で解放してしまえばいいのです。
しかし動かない
あとは簡単、ドライバをビルドしてテストするだけ、だと思ってたのですが、うまくいきませんでした。
パケットを送信しようとしても、Ethernetヘッダの前に謎の2バイトがくっつくという謎のバグが発生しました。

このドライバを通るすべての送信パケットでこの現象が発生するので、そもそもpingが通る云々以前にARP requestすらもロクに送れないのです。
原因を探る
まずはskb->dataの(物理)アドレス値をダンプしてみました。すると、下1桁がすべて2になっています。
ここで1つ思い当たったのがDMAの制約です。今回のNICはARM向けで、NICはAXIバス(ARMのバス規格)で接続しています。
AXIバスは8バイト境界でしか転送が行えないため、下1桁が2のアドレス値を渡しても切り捨てされたアドレス値で転送してしまい、結果として先頭にゴミ2バイトがついてしまうということはわかりました。

しかし、そもそもなぜアドレス値の下1桁がすべて2になっているのか?
次にskb->headのアドレス値をダンプしてみました。こっちは下1桁が0にちゃんとなっているんですよね。つまり、カーネルのネットワークスタック内で謎の2バイトがheadとdataの中に挿入されているわけです。

じゃあなんでネットワークスタック内で2バイト入れられてるのかというと、答えはこのマクロでした。
Linux/include/linux/skbuff.h - Linux Cross Reference - Free Electrons
#define NET_IP_ALIGN 2
これ何かというと、sk_buffを確保しているときに2バイトだけアラインメントを入れているんですね。例えばalloc_skb関数のラッパーとしてこんなのがあります。
static inline struct sk_buff *__netdev_alloc_skb_ip_align(struct net_device *dev, unsigned int length, gfp_t gfp) { struct sk_buff *skb = __netdev_alloc_skb(dev, length + NET_IP_ALIGN, gfp); if (NET_IP_ALIGN && skb) skb_reserve(skb, NET_IP_ALIGN); return skb; }
Linux/include/linux/skbuff.h - Linux Cross Reference - Free Electrons
skb_reserve関数はskb->dataを指定バイト数だけ進めてヘッダ領域を確保する関数です(生のhead / data / tail / endを扱うのは望ましくない)。ご丁寧にそもそも2バイト多く確保して、頭に2バイトくっつけてるのです。
これはTCP/IPのせせこましい歴史的経緯に由来しています。ところでみなさん、Ethernetヘッダって何バイトか覚えてますか?(これで2バイトの意味がわかったら相当すごいと思うんですが)
struct ethhdr { unsigned char h_dest[ETH_ALEN]; /* destination eth addr */ unsigned char h_source[ETH_ALEN]; /* source ether addr */ __be16 h_proto; /* packet type ID field */ } __attribute__((packed));
Linux/include/uapi/linux/if_ether.h - Linux Cross Reference - Free Electrons
ちなみにIPv4ヘッダはこんな構造になっております。
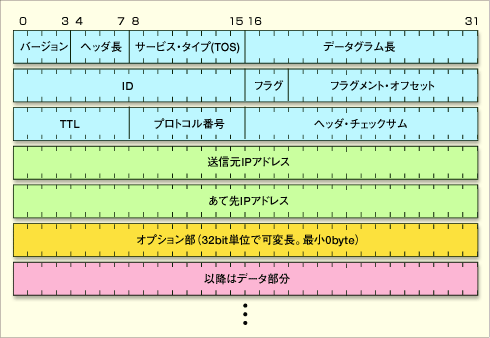
基礎から学ぶWindowsネットワーク:第10回 IPパケットの構造とIPフラグメンテーション (2/3) - @IT
注目してほしいのは「送信元IPアドレス」「宛先IPアドレス」です。これらはIPヘッダ内では4バイトアラインになっています。
しかし、Ethernetヘッダが頭にくっつくと、Ethernetヘッダ長が14バイトという中途半端な値ゆえ、4バイトアラインではなくなってしまいます。
多くのアーキテクチャでは4バイトアラインになってないメモリアクセス(アラインメント違反)を起こすと(キャッシュを何回もひかないといけないなどの事情で)パフォーマンスが低下します。
送信元IPアドレスや宛先IPアドレスはカーネルも頻繁にアクセスするため、できればアラインメント違反は起こしたくないので、それを避けるためにわざわざ2バイトのIPアラインを挿入しているのです。
ただし、これは古いアーキテクチャの話で、最近のx86だとかPowerPCだとアラインメント違反に起因するパフォーマンス低下はそこまででもないため、NET_IP_ALIGNは0になっています。
Linux/arch/powerpc/include/asm/processor.h - Linux Cross Reference - Free Electrons
Linux/arch/x86/include/asm/processor.h - Linux Cross Reference - Free Electrons
この辺(↑)参照。