スパコン「京」を探る

先日科学の甲子園のエクスカーションで、理研の計算科学研究機構におじゃまさせていただく
機会をいただき、理研と富士通が共同開発しているスパコン「京」を見学してきました。
そのときにも書いていますが、質問攻めの挙句名刺まで頂いてしまったので、
折角ですし、きちんと質問をしてからまとめてみたいと思います。
・「京」とは?
今や某国会議員の「2位じゃダメなんですか?」発言ですっかり有名なスーパーコンピュータ「京」。
半年に一度開かれる世界のスパコンのランク付け「TOP500」で世界一位を記録し続けています(2012/4月現在)。
その性能は10PetaFLOPSにもなり、それが"京(=10^16)"のネーミングの由来にもなっています。
PetaFLOPS
1FLOPSとは1秒間に1回の浮動点小数演算ができる性能。
1PetaFLOPSとはその10^15倍の性能。
つまり、10PetaFLOPS=10^16FLOPSである。
完成予定は2012年9月で、具体的には以下のようなことに使われるそうです。
予測する生命科学・医療および創薬基盤
新物質・エネルギーの創成
防災・減災に資する地球変動予測
次世代ものづくり
物質と宇宙の起源と構造
これは個人的関心なのですが、量子力学におけるシュレディンガー方程式は、
正確に近似せねば解となる波動方程式を求めることができず、その計算にも使われるだとか。
・ハードウェア構成
CPU : SPARC 64 VIIIfx(2GHz)
メモリ: DDR3 SDRAM
OS : Linuxベース
ここからは質問した内容です。
・ファイルシステムについて
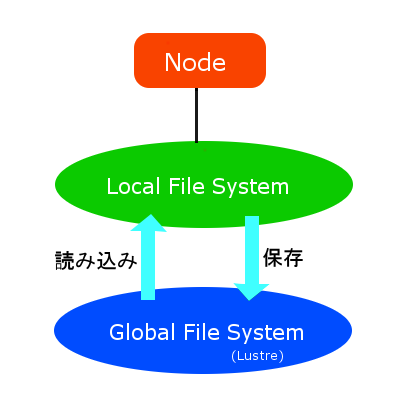
Oracleが開発したLustreというファイルシステムを拡張しています。
ファイルシステムが、ローカルファイルシステムとグローバルファイルシステムの二層構造に
分かれています。
基本はローカルファイルシステムで作業し、グローバルファイルシステムに保存する、という
形のようです。
ローカルファイルシステムでは、実行している並列プログラムが、他で実行しているプログラムに
影響されないように工夫がなされているそうです。
・ネットワークについて

京は、その高速演算能力を最大限活用するために、CPU間の通信も高速にしなければなりません。
そのため、隣り合うCPUとの通信経路を多くし、最短距離で通信できる「6次元メッシュ/トーラス」構造を
採用しています(概念図参照)。
これを"Torus Fusion"、略してTofuと呼んでいます。
Tofuには通信距離の短縮化以外にも、「1箇所が故障しても他の経路が使えるため故障に強い」という
メリットもあります。
OSもTofuや8万ノードという大規模に対応しています。
例えば、Linux、というより一般的なOSにおけるネットワーク通信ではTCP/IPがデファクトスタンダード
なので、socket通信を使うのが標準です。
しかし、socket通信ではメモリコピーや割り込み等、至る所でシステムコールを呼び出しています。
そのため、カーネルにアクセスする回数が必然的に多くなるため、オーバーヘッドが起こり、
処理能力の低下が免れません。
これを削減する工夫もあるそうです。
また、ノード間の通信にはMPIという並列プログラミングのインターフェースを採用しています。
MPI
Message-Passing Interfaceの略。CまたはFORTRAN用のライブラリである。
並列プログラミングを行うための、マシン間通信のインターフェースを提供している。
ソケットはネットワーク用のインターフェースだが、MPIはあくまで並列処理を
念頭に置いているため、マシン間通信を簡単に行うことができる。
・開発について
OSはLinuxベースですので、C言語を使ってほとんどが記述されています。
また、アプリケーションにはC、C++、FORTRANを使うことができます。
さらに、並列処理にはOpenMPというライブラリが使用できるそうです。
Open MP
こちらも並列処理用のインターフェース。
プリプロセッサディレクティブなどを使った簡潔な表現で並列処理ができる反面、
速度面ではややMPIに劣る。
僕はネットワークプログラミングや並列プログラミングはほとんどと言っていいほどわからないし、
さしてLinuxの仕組みについて理解しているわけでもないですが、
これらについて知るきっかけになった気がします。
オーバーヘッドの削減などはまだまだ興味深い部分もあるので、解決策を考えてみたいです。